Data URLs versus rotating presigned HTTPS: latency and cache in multimodal chat APIs
Benchmarks whether sending PNG bytes inline as Base64 data URLs or as Cloudflare R2 presigned HTTPS URLs changes multimodal completion latency. Three LLMs on synthetic OCR.
On every tested model, mean data: completion latency beat fresh presigned HTTPS (+13%, +23%, +39% presigned slowdown, by tier).
Caching tracks the image, not the URL text, for Gemini, OpenAI, and Anthropic here. Rotating presigned URLs did not look like wiping cache just by changing the link on any stack.
From habit to hypothesis
I got used to presigned HTTPS URLs for multimodal payloads. Stored chat JSON stayed small because I did not embed full image bytes in every message. The provider fetches the PNG over HTTPS on their side. I assumed I was moving traffic off my laptops and servers.
A teammate asked a simple follow-up: aside from RAM and log size, does that pattern really make completions faster? This post is what I measured.
My guess was that presigned wins on elapsed time because download at the provider would beat me sending Base64 again on every turn. I had no data, only a gut feeling.
That picture weakens when you remember requests already leave my machines on fast datacenter uplinks. OVH, AWS, and similar hosts are built to accept uploads. Assuming the provider always wins on fetch versus one more POST with the image inside is a rough shortcut for that setup. Slow home upload, mobile, or strict bandwidth caps can still change the tradeoff. So I ran a benchmark.
OCR as the benchmark task
OCR was a good fit. Current multimodal models already do well on clean synthetic screenshots. Outputs are nearly repeatable. I can generate endless labeled pairs in code instead of tuning hand-written creative prompts.
The synthetic pages stick to one recipe: five OCR lines of about ten words each, light backgrounds, fixed layout.
The setup ties each page to fixed ground-truth text baked into the image. Each assistant reply gets compared to that target string with rapidfuzz, yielding a similarity score from 0 (no overlap) through 1 (exact transcript). temperature is 0. Replies stay inside one fenced Markdown code block.
Images live in Cloudflare R2 for presigned. data: reads files from disk and sends Base64.
Main numbers rotate presigned URLs on every replay (including older history rows) so logs never reuse stale URL strings by accident. I also ran presigned with one fixed HTTPS URL whenever the same PNG comes back.
Latency versus data: looked the same in both setups, so rewriting the signature did not read like a latency win in what I captured. Nothing in these traces suggested multimodal backends reuse prior HTTPS fetches just because the PNG URL matched an earlier request; completions still behaved like vendors pay for decode plus HTTPS pull, not like a warmed URL-aware shortcut.
I use 3 vendors, smaller multimodal models (Gemini, GPT, Claude, names below). Larger tiers should behave in the same ballpark, but this run does not prove that for every model.
Avoid mixing cached work between lanes
To compare data: with presigned without one side reusing image cache hits meant for the other, I generate paired PNG layouts (A: white background, dark text; B: off-white background, charcoal text). Same wording, slightly different RGB, different hashes and bucket keys, hard to spot by eye. data or presigned receives A or B at random each time.
Example from series 6, turn 6 in the generator (a / b files). Same transcript; two skins so bytes never match between lanes while the page still reads the same to a human.
 Variant
Variant a in the generator: higher-contrast white backdrop and dark type.
 Variant
Variant b in the generator: slightly tinted backdrop and softened ink so the raster hash diverges.
For presigned, histories use a fresh signed GET URL whenever an image appears, including turns already stored earlier in the thread.
Method shape and timer
The benchmark harness ran on an OVH VPS in a datacenter. I did not drive it from my home machine on purpose: residential upload is often the weak link for large multimodal payloads, and I wanted timings closer to what you get from a production-style host on a datacenter link. Presigned objects live in Cloudflare R2, so the vendor fetches PNGs from R2 over HTTPS while the API client runs on that same VPS. That way both data: reads from local disk and presigned fetch paths are not dominated by consumer broadband jitter or caps.
Runs use series and turn depth.
Ten independent chats (series) with unrelated text. Inside each, ten turns, index 0 through 9, calls run strictly one after another.
Turn 0: one PNG plus a short OCR instruction. Turns > 0: send full history plus one new PNG.
total_time_ms runs from starting the multimodal request until the last assistant token arrives. Signing, disk read, and Base64 encoding (when used) finish before that timer starts.
Replay outline (one series, one delivery path):
flowchart LR
subgraph warmup [Before timed calls]
R2[R2 PNG objects uploaded]
IDX[Index rows per serie turn method]
end
subgraph per_series_per_method [Replay one series]
T0["Turn 0: user PNG plus OCR brief"]
T0 --> A0["Assistant OCR"]
A0 --> T1["Turn 1: full history plus new PNG"]
T1 --> A1["Assistant OCR"]
A1 --> Tn["Turns 2 through 9 repeat pattern"]
end
warmup --> per_series_per_method
Wire formats
| Method | Payload shape |
|---|---|
data |
data:image/png;base64,... inside the multimodal POST |
presigned |
Fresh Cloudflare R2 HTTPS GET URL for each emission and replay |
PNG canvas 1920 x 1080. Model identifiers in logs: gemini-flash-2.5 (flash-2.5), gpt-5.4-mini, claude-haiku-4.5 (haiku-4.5).
Operational notes
- OpenAI and Gemini turned on prompt caching with defaults in this harness. Claude requires explicit
cache_controlon the multimodal payloads you intend to cache; without it Anthropic prompt caching stays off. - Vendors expose cached-input totals under different shapes; compare rows cautiously rather than stacking them blindly.
- Where Claude caching was active, ephemeral TTL stayed at 5 minutes.
- Some stacks prefetch HTTPS-linked PNG bytes on the client before timing. That work stays outside
total_time_ms.
This benchmark compares inlined PNG bytes in data: requests with presigned HTTPS GETs routed through Cloudflare R2.
Question 1: Same accuracy on both lanes?
If rapidfuzz scores disagree, latency numbers are pointless.
Result: mean score 1.0 (100 transcripts each model and method). Choosing data: or presigned did not break OCR accuracy here.
Question 2: Does URL rotation break cache counters?
Side question: every presigned URL string is new each time. Do vendors treat the image as brand new and zero the cached-input totals they expose?
Across replay with fresh signatures, including older turns, claude-haiku-4.5 still showed equal mean cached-input token counts for data and presigned. That lines up with the image driving those counters, not the URL alone, inside each completion payload.
Separate runs reused one stable presigned HTTPS string per PNG, without issuing another signature whenever history repeats. Cached-input counters moved like the rotated-URL batches, which sits well with lumping ordinary static CDN links into the same story on whether rewriting the HTTPS string clears those counters all by itself.
| Combination | Cached input tokens (mean) |
|---|---|
gemini-flash-2.5 / data |
964 |
gemini-flash-2.5 / presigned |
823 |
gpt-5.4-mini / data |
8474 |
gpt-5.4-mini / presigned |
8950 |
claude-haiku-4.5 / data |
7175 |
claude-haiku-4.5 / presigned |
7175 |
Claude shows the same mean cached-input count for data and presigned. I thought Gemini and OpenAI would too. They do not. I only set explicit cache_control for Claude here. For Gemini and OpenAI I left vendor defaults. Something in those defaults likely treats data: and presigned paths differently. I do not know every knob on their side.
I first ran Claude without setting cache_control. That was a mistake: Anthropic only enables this cache path when you mark it explicitly. Loads of data: requests came back BadRequestError with a PNG download timeout message from Anthropic's side. My client retries the call up to three times, which sometimes unstuck it, but it mostly felt like data: image sends freezing and then succeeding late. Turning cache_control on flattened the failures and trimmed spend. Numbers in the main table still skew faster on data:. During the bad window, presigned tended to survive more cleanly if you optimize for uptime. None of those failure runs feed the published means above.
Question 3: Which path finishes faster?
Each cell pools 100 timed calls (10 series, 10 turns). Totals come from summary_by_model_method.
| Model | Data mean (ms) |
Presigned mean (ms) |
Presigned slowdown |
|---|---|---|---|
| gemini-flash-2.5 | 2832 | 3200 | +13% |
| gpt-5.4-mini | 1854 | 2280 | +23% |
| claude-haiku-4.5 | 2689 | 3749 | +39% |
presigned means the vendor pulls the PNG over HTTPS. data: means you already inlined the PNG in the HTTPS POST.
Figure: latency vs turn index
Averages across ten chats per plotted turn. Solid blue is data. Dashed red is presigned. Markers: circle gemini-flash-2.5, square gpt-5.4-mini, triangle claude-haiku-4.5.
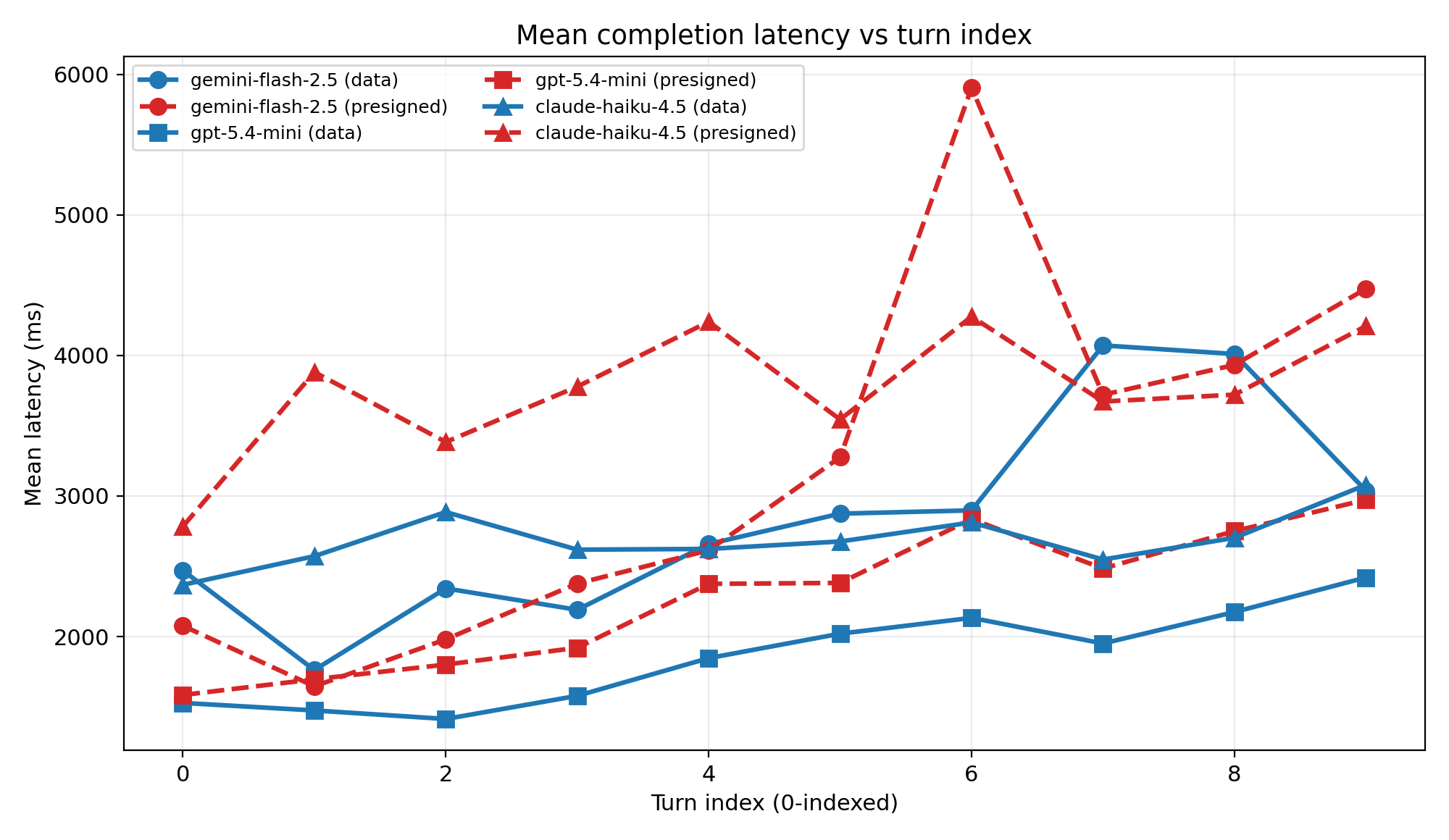
Single turns swing a lot (queue, longer context). The averaged table still has presigned slower. Gemini can sit below data: on early turns, so I rely on means and the chart together.
What caught me off guard
I expected a tie or a presigned win because my day job habits favor small logs and less RAM, not milliseconds. Mean total_time_ms rose about 13% to 40% when the vendor had to GET from R2 instead of parsing inline Base64 (model dependent), on the same OVH VPS with matching upload and download speed.
Cached-input counts also did not match my neat guess.
Closing take
If you only care about shortest median completion time on this OCR setup, pick data:. Presigned still wins when upload is slow, when you reuse the same images in long chats, or when you need less RAM or smaller stored chats. Those goals sit next to latency; they do not replace it.
I only wired this benchmark through OpenAI, Google Gemini, and Anthropic. I still expect the same directional story on other multimodal hosts, but treat that as guesswork until somebody runs the same split on their APIs.